ヴォイニッチ手稿の文字頻度と文字Bi-gram
前回に引き続き,ヴォイニッチ手稿の基礎的な統計分析をしていきます.
今回は,ヴォイニッチ手稿に出てくる文字の頻度を解析します.
前回のプログラムを少し変更するだけです.
#coding: utf-8 #ヴォイニッチ手稿の文字カウント import sys from collections import Counter C = Counter() for line in sys.stdin: line = line.strip() if len(line)==0: continue if line[0]=="#": continue terms = line.split(",") for term in terms: C += Counter(term) print "word\tcount" for w,c in C.most_common(): print w,"\t",c
注意点として,今回使っているトランスクリプションは,ヴォイニッチ手稿の文字の内複雑なものを,複数の文字で表しています.
例えば以下の文字は,PZと2文字で表しています.
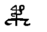
今回はこのような複数文字も分解して1文字と考えてカウントしています.
精度の低い分析ですが,あたりを付けるためのものなのでこれで良しと,勘弁してください.
いずれ,文字をデータにする関数として定義していきたいですね.
集計結果が以下になります.
前回の単語頻度分布と同様,指数分布になっています.
文字の分布も,一般的な言語と近しい性質を持っていそうです.
Oが一番多い文字のようです.
6600個あり,全体の15%以上を占めます.
Oは元の文字としてもただの丸という簡潔なものなので,書きやすそうです.
頻出の文字には書きやすいものを当てたいというのは自然ですので,これが最多というのは,言語を作る(或いは自然と作られる)上で納得がいくように思えます.
ひょっとすると,a,anのような冠詞を表していたり,あるいは読点のような文の切れ目を表していたりするかもしれません.
Oにそのような役割があるか,予想をすることはできるでしょうか.
これについては,次回考察してみたいと思います.
今回は,Oが冠詞や読点である可能性を考える材料として,Oが連続出現しているかどうかを調べておきましょう.
文字の連続性を調べるために,文書中の,2つ連続する文字を1とカウントして,文字数を集計します.
このように,文字を2つずつ繋げたものを文字2-gram(バイグラム)と呼びます.
例えば,ヴォイニッチ手稿の1ページ目の一番最初の単語
FGAG2
は,
F,FG,GA,AG,G2,2をひとつずつカウントします.
文字2-gramをカウントするプログラムが以下です.
#coding: utf-8 #ヴォイニッチ手稿の文字Bi-gramカウント import sys from collections import Counter C = Counter() for line in sys.stdin: line = line.strip() if len(line)==0: continue if line[0]=="#": continue terms = line.split(",") for term in terms: for c1,c2 in zip(["$"]+list(term),list(term)+["$"]): bi = "".join([c1,c2]) C[bi] += 1 print "word\tcount" for w,c in C.most_common(): print w,"\t",c
単語の先頭と最後尾に"$"を付けて,zip関数を使って2つずつ取っています.
わざわざ"$"を付けるのは,単語の先頭の文字と最後尾の文字を1文字にしてしまうと,先頭と最後尾に出現した文字をともにカウントしてしまうので,それを防ぐためです.
この結果が次のグラフになります.
文字2-gramの結果は,興味深い性質をいくつか示してくれます.
Oの意味を推測する前に,先にそちらの性質を考えていきます.
まず,一番多い2文字は"G$"であることがわかります.
つまり,Gは単語の最後尾に来ることが圧倒的に多いということを示します.
当分析で用いているトランスクリプションでは,ヴォイニッチ手稿の元々の一行の最後尾であることを"-"で示しています.
そのため,"-"の次には必ず"$"が来るため,"-$"という2文字は行の数に比例して存在します.
ところが,"-$"の出現回数は1456個であるのに対し,"G$"は3046個と,倍以上出現しています.
これは,Gで終わる単語が1行に平均2回出現していると考えられます.
そもそも,文字Gの出現回数は4530個です.
よってGが出現したときに,単語の最後尾に出現している確率は
3046 / 4530 = 0.67
と,実に2/3以上となります.
Gは元々文書全体の10%程度しか占めていなかったことを考えると,圧倒的な最後尾での出現頻度ですね.
単語の最後にGを付けることが,意図して起こっている,と言えそうです.
なお,このようなある条件下(例えば単語の最後尾という条件)である事象(例えばGが出現する)という確率は,条件付き確率と呼びます.
この条件付き確率は,後の分析でも重要な役目を持ちますので,いずれ別途説明したいと思います.
Gの他にも,最後尾に出現しやすい文字としては,"R$"(1506個),"E$"(1272個),"M$"(1118個)などがあります.
どちらも1行に1個程度,最後尾に付けられた単語があります.
各文字はそれぞれ1400〜2000個程度しか存在しないことを考えると,
これらの文字R,E,Mも,最後尾に出現することが多い文字と言えます.
上記のように,最後尾に出現しやすい文字があることがわかりました.
では,先頭に出現しやすい文字はどうでしょうか?
$が前に付いた2文字だけを取り出し,頻度を集計した結果が以下です.
T,O,8が,他の文字と比べて突出して多いです.
ただ,Oは元々文書全体の15%を占める,出現回数の多い文字でした.
一方,$が前につく2文字10031個の内,"$O"1668個は,
1668/10031=0.166
と,16%程度です.
Oの出現を単語の先頭に限定して見ても,出現確率は僅かに上がる程度です.
Oは単語の先頭に出やすい,とは必ずしも言えないようです.
一方,T,8の出現確率は,それぞれ全体の8%程度しか占めていなかったのに対し,
先頭に限定すると,出現確率が17%,15%程度まで跳ね上がります.
T,8は単語の先頭に出現しやすい,と言って差し支えなさそうです.
まとめると,
・G,R,E,Mは単語の最後尾に出現しやすい文字
・T,8は単語の先頭に出現しやすい文字
・Oは特定の箇所に出現しやすいとは,現段階では確証を持っては言えない
となりました.
次回はOの持つ役割について,引き続き文字数の頻度集計結果を使って考察していきます.