2017/10/13 収支報告 ~日経平均株価が絶好調ですが,我が家はウルフ村田氏だけが影響しています~
2017/10/13,9週目の収支報告です.
先週に信用取引を行うと述べていたのですが,諸事情で忙しく,リスクのある取引を行う前に十分検討できる時間が取れませんでした.次回に持ち越しです.
続いて,保有株式です.
サンメッセを売却しました.
日経平均が20年ぶりの高値回復ということですが,マザーズが多い私の保有銘柄はさほど恩恵を受けず,通常通りの利益になっています.KDDIさんェ...
というか,今週はマイナスで終わるかと思っていたのですが,最後の最後で保有していたサンメッセがストップ高となり,売却したことで好調な結果となりました.
心当たりのない急騰だったのですが,Yahoo!!ファイナンスの掲示板を見ると,ウルフ村田氏がサンメッセに対して言及したたためのようです.S高でちょうど想定していた価格を超えたため,お昼に売り抜けました.
利益は9週で9万超えの+11.3%でした.キレイに週1万のペースで儲けてます.複利の効果が出ていないですが,80万でこの額は十分すぎる結果ではないでしょうか.
ウルフ村田氏など発言力のある人物の言葉によって銘柄を購入する,いわゆるネットイナゴですが,実際のところ儲かっているんでしょうかね?
ネットイナゴ自体は,市場の盛り上げ役という見方もあるので,私はそこまで否定的でないです.ただ,こうやってお陰様で儲けている私のような人物がいるゼロサムゲームだと考えると,なかなかその手段で儲けるのは簡単でないように思えます.まぁ,儲かっているからこそ,そうした方々が居なくならないのかもしれませんが.
私の方は日経平均に影響も受けず,仕手株にも手を出さず,引き続き自分の信じた,確率論に基づく銘柄選定手法を続けていこうと思います.
2017/10/06 株式投資の収支報告 ~KDDIを購入~
今週の株式投資の収支報告です.
売り買いが比較的激しい週でした.
黒字ではありますが,小幅上がりと言ったところです.
これでも十分に利益が出ている方ですが,できれば週10,000は儲けたいところです.
保有銘柄はこちら.
ひらまつ,スペースシャワー,NTT都市開発を売りました.
そして,KDDIを購入しました.保有銘柄の中では圧倒的に時価総額と出来高の大きい銘柄です.しばらくは保有しているつもりですが,日経平均が絶好調の今の時期,大手銘柄は少し今更感もある1手ではありますがどうでるでしょうね.
8週目までの利益総額は\76,400で,利益率は9.6%となっています.ここまでは日経平均が好調だったことも有り,かなり順調な数値を叩き出してきました.ただ,ここ暫くは少しずつ利益が鈍化しております.
手法的にも各銘柄の投資額は控えめで,分散を強めにしており,もう少しレバレッジを効かせて,リスクを大きく取っても良いと考えています.
そこで,信用取引を使ってテコ入れしていくことを,試験的に行なっていこうと思います.
今週早速信用取引をすることも考えましたが,連休であるため金利が少々もったいなく,控えました.休み明けから,バランスシートに信用取引の項目を入れたいと思います.
2017/09/29 株式投資の収支報告
2017/09/29,株価予測に従う株式投資を始めてから7週目の収支報告です.
保有銘柄はこちら.
決算発表が近いレノバを,一旦売りました.
決算発表はリスクが伴うので,基本的に持ち越さないことにしているのですが,ただ今週はこの判断が裏目に出て,レノバの本日の値上がりに乗り損ねました.
結果,利益がギリギリ7万円に届かず,週1万の平均利益にわずかに届きませんでした.
決算発表時に持ち越さないのは継続するつもりですが,発表前は値上がりすることが多いので,ギリギリまで保有し続けたほうが良いのかもしれませんね.
それ以外の銘柄については,概ね好調です.
特にしばらく冴えなかった片倉が,ここに来て急上昇しました.
利益率は+8.7%でした.
7週でこの利益率は,まずまずといって良いと思います.
この調子で行きたいですね.
2017/09/22 株式投資の収支報告
2017/09/22 今週の株式投資の収支報告です.バランスシートがこちら.
月曜に祝日があり,4営業日のみでした.そのためあまり動かずに終わるかなと思ったのですが,最後の金曜に割りと大きく下がり,\6,300の減となりました.
保有銘柄はこちら.新規に2銘柄を購入しました.
NTT都市開発は月曜に下がったところを,アイドママーケティングは今日金曜に下がったところを買いました.
機械学習を用いて株価の上がる確率を予測し,投資銘柄を決めています.
意外と株価の変動が激しく,予測確率が変動しやすいため,スイングトレード(数週~数ヶ月程度でのトレード)になっています.
現時点での利回りは6週で約6.5%となっています.割と上々の結果ですね.
ただ,ここまでは時合いの良さに助けられていた雰囲気もありました(といっても北朝鮮問題があったり,日経平均は上がってもマザーズは下げ調子だったりと格段に良いわけでもないのですが).
ここからはこの投資方法が本当に有効なのかどうかが問われるところです.
2017/09/20 株式投資の収支報告
8がつから,資産のうち80万円に限定して,株式投資をやっています.
正確には株式投資自体は前々からやっていて,下の銘柄以外にも保有しているんですけど,機械学習を使って銘柄の株価予測を行ない,その結果を使って,全80万で投資しています.
毎週金曜にその結果をバランスシートとして書いているので,その結果を公開していくことにします.先週末の結果がこちら.
左側の資産の部は,投入資金が株式と現金のどちらで保有されているかを示しています.株式は,投資した額と含み益を内訳表示しています.右側の負債の部が,投資した初期投資資金(自己資本)と,利益総額(利益剰余金)を表しています.要は,利益剰余金が,これまでに儲けたお金です.
新規買い,新規売りと書かれているのは,その週に売り買いした株式の金額です.
えらく利益が増えていますが,これは前週が北朝鮮ミサイル発射からの情勢不安が解消されて,元の利益に概ね戻ったためです.投資を開始してからの経過週が,日にちの横に書いてあります.5週で5万ほど儲けているので,ざっくりとは週1万ほどの利益ですね.80万の投資で週1万の利益なら,継続すれば中々の利益です.
ただ,今週は日経平均も20000程度で留まり,それほど良い時合いではないので,週の損益は赤字になりそうです.もう少し利回り想定は下がるかも.
こうして書いてみると,バランスシートというものが良くできているものかがよくわかりますね.
利回りなんかも表示すると良さげなので,いずれ書くことにします.
現在の保有銘柄はこちら. SBI証券の口座内容をそのままコピペしています.
このデータは今日取ったものなので,上の保有株総額と合わないですのでご注意.
ひとつだけ信用取引で購入しているので,別に記載します.
いずれ,どのように購入銘柄を決めているかも書いていこうと思います.
しばらくは,毎週金曜に,その週の収支報告を続けていこうと思います.
ヴォイニッチ手稿の文字頻度と文字Bi-gram
前回に引き続き,ヴォイニッチ手稿の基礎的な統計分析をしていきます.
今回は,ヴォイニッチ手稿に出てくる文字の頻度を解析します.
前回のプログラムを少し変更するだけです.
#coding: utf-8 #ヴォイニッチ手稿の文字カウント import sys from collections import Counter C = Counter() for line in sys.stdin: line = line.strip() if len(line)==0: continue if line[0]=="#": continue terms = line.split(",") for term in terms: C += Counter(term) print "word\tcount" for w,c in C.most_common(): print w,"\t",c
注意点として,今回使っているトランスクリプションは,ヴォイニッチ手稿の文字の内複雑なものを,複数の文字で表しています.
例えば以下の文字は,PZと2文字で表しています.
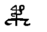
今回はこのような複数文字も分解して1文字と考えてカウントしています.
精度の低い分析ですが,あたりを付けるためのものなのでこれで良しと,勘弁してください.
いずれ,文字をデータにする関数として定義していきたいですね.
集計結果が以下になります.
前回の単語頻度分布と同様,指数分布になっています.
文字の分布も,一般的な言語と近しい性質を持っていそうです.
Oが一番多い文字のようです.
6600個あり,全体の15%以上を占めます.
Oは元の文字としてもただの丸という簡潔なものなので,書きやすそうです.
頻出の文字には書きやすいものを当てたいというのは自然ですので,これが最多というのは,言語を作る(或いは自然と作られる)上で納得がいくように思えます.
ひょっとすると,a,anのような冠詞を表していたり,あるいは読点のような文の切れ目を表していたりするかもしれません.
Oにそのような役割があるか,予想をすることはできるでしょうか.
これについては,次回考察してみたいと思います.
今回は,Oが冠詞や読点である可能性を考える材料として,Oが連続出現しているかどうかを調べておきましょう.
文字の連続性を調べるために,文書中の,2つ連続する文字を1とカウントして,文字数を集計します.
このように,文字を2つずつ繋げたものを文字2-gram(バイグラム)と呼びます.
例えば,ヴォイニッチ手稿の1ページ目の一番最初の単語
FGAG2
は,
F,FG,GA,AG,G2,2をひとつずつカウントします.
文字2-gramをカウントするプログラムが以下です.
#coding: utf-8 #ヴォイニッチ手稿の文字Bi-gramカウント import sys from collections import Counter C = Counter() for line in sys.stdin: line = line.strip() if len(line)==0: continue if line[0]=="#": continue terms = line.split(",") for term in terms: for c1,c2 in zip(["$"]+list(term),list(term)+["$"]): bi = "".join([c1,c2]) C[bi] += 1 print "word\tcount" for w,c in C.most_common(): print w,"\t",c
単語の先頭と最後尾に"$"を付けて,zip関数を使って2つずつ取っています.
わざわざ"$"を付けるのは,単語の先頭の文字と最後尾の文字を1文字にしてしまうと,先頭と最後尾に出現した文字をともにカウントしてしまうので,それを防ぐためです.
この結果が次のグラフになります.
文字2-gramの結果は,興味深い性質をいくつか示してくれます.
Oの意味を推測する前に,先にそちらの性質を考えていきます.
まず,一番多い2文字は"G$"であることがわかります.
つまり,Gは単語の最後尾に来ることが圧倒的に多いということを示します.
当分析で用いているトランスクリプションでは,ヴォイニッチ手稿の元々の一行の最後尾であることを"-"で示しています.
そのため,"-"の次には必ず"$"が来るため,"-$"という2文字は行の数に比例して存在します.
ところが,"-$"の出現回数は1456個であるのに対し,"G$"は3046個と,倍以上出現しています.
これは,Gで終わる単語が1行に平均2回出現していると考えられます.
そもそも,文字Gの出現回数は4530個です.
よってGが出現したときに,単語の最後尾に出現している確率は
3046 / 4530 = 0.67
と,実に2/3以上となります.
Gは元々文書全体の10%程度しか占めていなかったことを考えると,圧倒的な最後尾での出現頻度ですね.
単語の最後にGを付けることが,意図して起こっている,と言えそうです.
なお,このようなある条件下(例えば単語の最後尾という条件)である事象(例えばGが出現する)という確率は,条件付き確率と呼びます.
この条件付き確率は,後の分析でも重要な役目を持ちますので,いずれ別途説明したいと思います.
Gの他にも,最後尾に出現しやすい文字としては,"R$"(1506個),"E$"(1272個),"M$"(1118個)などがあります.
どちらも1行に1個程度,最後尾に付けられた単語があります.
各文字はそれぞれ1400〜2000個程度しか存在しないことを考えると,
これらの文字R,E,Mも,最後尾に出現することが多い文字と言えます.
上記のように,最後尾に出現しやすい文字があることがわかりました.
では,先頭に出現しやすい文字はどうでしょうか?
$が前に付いた2文字だけを取り出し,頻度を集計した結果が以下です.
T,O,8が,他の文字と比べて突出して多いです.
ただ,Oは元々文書全体の15%を占める,出現回数の多い文字でした.
一方,$が前につく2文字10031個の内,"$O"1668個は,
1668/10031=0.166
と,16%程度です.
Oの出現を単語の先頭に限定して見ても,出現確率は僅かに上がる程度です.
Oは単語の先頭に出やすい,とは必ずしも言えないようです.
一方,T,8の出現確率は,それぞれ全体の8%程度しか占めていなかったのに対し,
先頭に限定すると,出現確率が17%,15%程度まで跳ね上がります.
T,8は単語の先頭に出現しやすい,と言って差し支えなさそうです.
まとめると,
・G,R,E,Mは単語の最後尾に出現しやすい文字
・T,8は単語の先頭に出現しやすい文字
・Oは特定の箇所に出現しやすいとは,現段階では確証を持っては言えない
となりました.
次回はOの持つ役割について,引き続き文字数の頻度集計結果を使って考察していきます.
ヴォイニッチ手稿の単語頻度分析
さて,前回はヴォイニッチ手稿のトランスクリプトデータをダウンロードしました.
shounena.hatenablog.com
今回は,これを使ってまずはざっくりと,傾向をデータ分析しようと思います.
目的は,ヴォイニッチ手稿が意味のある文書なのか,それとも適当に文字っぽいものを並べただけのものなのか,その見当をつけることです.
まずは,基本の分析として,ヴォイニッチ手稿の単語数を集計します.
#coding: utf-8 #ヴォイニッチ手稿の単語カウント import sys from collections import Counter C = Counter() for line in sys.stdin: line = line.strip() if len(line)==0: continue if line[0]=="#": continue terms = line.split(",") C += Counter(terms) print "word\tcount" for w,c in C.most_common(): print w,"\t",c
このプログラムは,こんな風にcatコマンドと組み合わせて使います.
cat ../FSG.txt | python wordcount.py
入力データは,FSG.txtです.
タブ区切りで出力するので,適当にresult.tsvなどと名前をつければ,Excelなどで表示可能です.
出力結果は数の多い順に並んでいます.
結果をグラフにしてみました.
ちなみに,このプログラムでは文節終わりを示す=がついた"8AM="などは別単語扱いです.
ひどく雑な集計ですが,初歩分析ということで勘弁下さい.
その内キチンと修正します.
単語の分布の形は,指数的な分布,Zipf則に従っているように見えます.
一般には,この形状がヴォイニッチ手稿が適当な記号列ではなく,何か意味がある文書だという根拠のひとつとなっています.
ヴォイニッチ手稿は未だに解明できないこともあり,ただのイタズラであるという可能性も否定できません.
ただ,人間が意識せずに意味のない文字列を作ると,一般にはこのような指数分布にすることは難しく,出現に偏りの少ない,均一分布に近くなります.
その点,この文書は単語の偏りが一般的な言語と同じ指数分布という性質を示しており,不規則に単語っぽいものを並べたということは考え難いです.
ということで,ヴォイニッチ手稿は
・不規則に単語を並べただけではなく,何らかの規則性を持って並べられた,意味を持った文字列である可能性が高い
と言えます.
ただ,例えば文書を作った後に不規則に単語を並べ替えたなど,文としては成立していないことも考えられます.
これについては後の分析で改めて検証していきます.
出現数としては,8AMという単語が圧倒的に多いです.
全単語数10031個に対し,360個と4%近くを占めます.
これは英語での出現単語と比べると偏りはやや少ないといえます.
英語における出現数が最も多い単語は通常"the"であり,一般的な文書では概ね8%程度です.
次に多い単語はtoで4%程度,またa,anも合わせると4%程度です.
8AMという単語だけで見ると,出現頻度的には少ないと言えるかもしれません.
ただし,これは"8AM"という単語と完全一致した物の数だけです.
手稿の中には"8AMが含まれる単語"も多くあり(例えば"O8AM"というものは22個),
これを合計すると641個と,冠詞の出現数と比較的一致します.
例えば8AM,が名詞の前後にくっつけて冠詞として動作する,という可能性はあります.
ただ,現時点ではこの断定は難しそうです.
8AMに次いで,TOE,TORという単語が多いです.
このT**という単語は比較的多く存在します.
Tという文字を付けることは,何らかの意味があるのかもしれません.
次は文字頻度について分析してみます.

たった58秒で作る Excel超簡単 ヒストグラム 「超簡単」シリーズ
- 作者: 寺田裕司
- 発売日: 2015/09/02
- メディア: Kindle版
- この商品を含むブログを見る